조선왕조실록 1만 건, 한국고전종합DB 3만 건, 승정원일기 3천 건. 박사 논문을 쓰면서 크롤링해 모은 사료가 약 5만 건이 됐다. 전부 JSON 또는 JSONL 형식으로 저장해두고 있다.
개선하고 싶었던 건 이 데이터를 열어보는 방식이었다. JSON 파일을 직접 열면 사람이 읽기엔 불편하다. 그렇다고 5만 건을 전부 마크다운 파일로 내보내는 건 비효율적이다. 원본이 이미 있는데, 같은 내용을 파일로 또 만들어서 저장해야 하나?
이 글은 사료를 “파일로 저장하지 않고도 편하게 열람하는” 로컬 웹앱 BESPOKE를 만든 과정이다. 이 과정에서 확인한 것: 사료를 파일로 출력하는 것과 화면에서 보는 것은 다른 개념이며, 이 구분을 알면 5만 건의 사료를 관리하는 방식이 달라진다는 것, 그리고 “나에게 맞는 방식으로 보고 싶다”는 니즈 자체가 앱 개발의 충분한 동기가 된다는 것.
모든 사료를 md로 뽑아야 할까
나는 크롤링한 사료를 마크다운 파일로 변환하지 않는다. JSON 원본 그대로 둔다.
왜? view와 materialize의 구분 때문이다.
view — 필요할 때 꺼내서 보는 것
view는 데이터를 파일로 저장하지 않고, 필요할 때 원하는 형태로 화면에 띄워 보는 것이다. 도서관에서 원문 자료집을 열람석에 꺼내 읽고, 다 읽으면 다시 서고에 꽂아두는 것과 비슷하다. 원본이 서고에 있으니까, 필요하면 다시 꺼내 보면 된다.
JSON 원본이 있으면 언제든 원문/번역 병렬로 보여줄 수 있고, 메타데이터를 붙여서 보여줄 수도 있고, 원문만 뽑아서 보여줄 수도 있다. 같은 데이터를 여러 방식으로 볼 수 있다.
materialize — 파일로 저장하는 것
materialize(실체화)는 데이터를 .md 파일 같은 형태로 디스크에 저장하는 것이다. 같은 내용을 포맷만 바꿔 복제하는 셈이다.
열람만을 위해 실체화하는 건 불필요하다 — 원본이 있으니 view로 보면 된다. 실체화가 필요한 건 두 가지 경우다. 내가 사료에 해석이나 분석을 붙이고 싶을 때 — 하이라이트를 치고 메모를 달고, 그 주석 작업 자체가 연구 산출물이 되는 경우. 또는 타인에게 공유해야 할 때. 이때는 파일로 저장해야 한다. 원본 사료와 별개로, 목적이 있는 새로운 파일이 생기는 것이다.
구분이 왜 중요한가
5만 건 사료를 전부 .md 파일로 내보내면 어떻게 될까?
- 저장 공간이 두 배로 든다 (JSON 원본 + md 사본)
- 원본이 업데이트되면 사본도 동기화해야 한다
- 5만 개의 .md 파일을 관리하는 부담이 생긴다
열람만 하는 거라면 view로 충분하다. 내 해석을 붙이는 순간 materialize가 필요해진다. 이 구분을 알면, “전부 파일로 뽑아야 하나?”라는 불안에서 해방된다.
나는 5만 건 중 실체화한 건 수백 건 정도다. 나머지는 JSON 원본 상태로 두고, 필요할 때 view로 열어본다.
그런데 JSON은 사람이 읽기에 불편하다
view로 충분하다는 건 알겠는데, 실제로 JSON 파일을 열어보면 이렇게 생겼다:
{
"id": "ITKC_MO_0367A_0030_020_0090",
"title_hanja": "步金生 榦 所次鐵嶺作",
"original": "早守遯翁說。肝石而心鐵...",
"translation": "일찍이 둔옹의 말씀 지키어..."
}이걸 수만 건씩 눈으로 훑는 건 고역이다. 나는 원문과 번역을 나란히 보고 싶고, 저자와 날짜와 출처를 깔끔하게 보고 싶고, 검색도 하고 싶다.
게다가 내가 모은 데이터의 유형마다, 보고 싶은 형태가 다르다.
- threads(스레드): 경전 원문 + 한국어 번역, 그 아래 주석가별 주석 카드. 카드에는 주석가 이름, 시대, 생몰년, 주석 원문, 번역이 들어간다.
- keyword(키워드 번들): 특정 키워드가 포함된 기사 수백 건을 목록으로 훑으며, 원문/번역 병렬로 열람.
- DB(실록, 문집 등): 소스별 번들에서 기사를 빠르게 검색하고 상세를 확인.
범용 JSON 뷰어로는 이걸 못 한다. 나에게 맞는 방식으로 렌더링해주는 도구가 필요했다. 그래서 로컬 웹앱을 만들기로 했다.
핵심 기능만 말했다
Claude와 앱을 개발하는 과정 자체는 이전에 Gloss 리더 앱을 만든 경험과 크게 다르지 않다. 불편함과 니즈를 말하면 Claude가 기술적 방법을 제안하고, 대화하면서 구체화하는 방식.
그간의 티키타카의 경험 상, 여러 기능을 한꺼번에 구현해달라고 하면 어딘가에서 반드시 에러가 난다. 그리고 기능이 얽힐수록 문제의 원인을 특정하기 힘들어진다. 그래서 이번에는 딱 핵심 기능만 먼저 구현하고, 필요한 기능이 생기면 그때 추가하기로 했다.
Claude(Opus)에게 요구한 것:
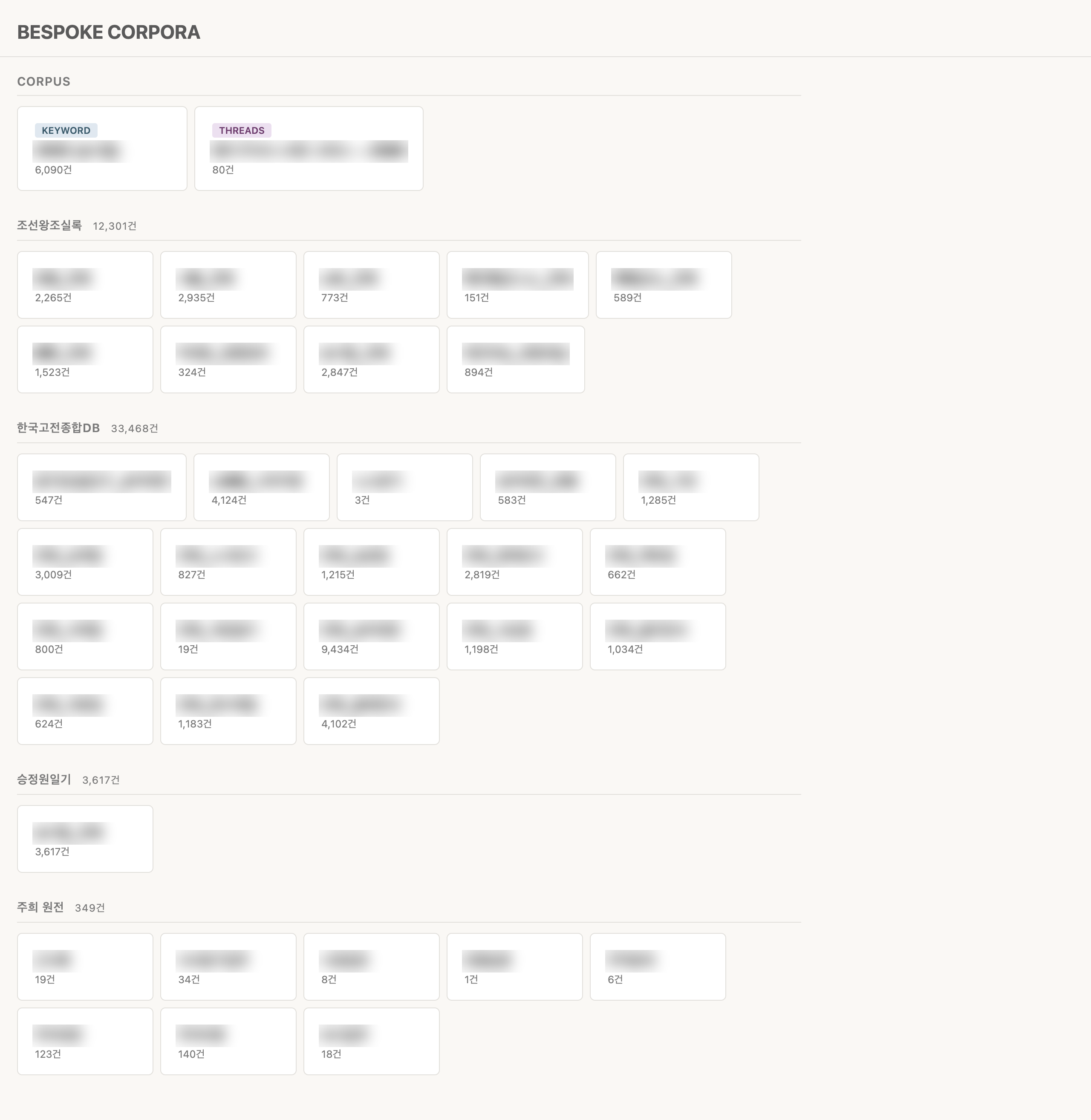
- CORPUS 폴더와 DB 폴더를 통합해서 메인 화면에 카드로 보여줄 것. CORPUS는 내가 직접 구축한 코퍼스(keyword 번들, threads 번들), DB는 크롤링한 원자료(실록, 문집, 승정원일기 등).
- keyword 번들 뷰어: 기사 목록(페이지네이션) + 상세 화면에서 원문/번역 병렬 표시.
- threads 번들 뷰어: 좌측 사이드바에 경전 세그먼트 목록, 우측에 세그먼트 원문·번역·주석 카드 표시. 주석 카드에는 주석가명, 시대, 생몰년, 주석 유형이 들어갈 것.
- DB 뷰어: 소스별(실록, 문집, 승정원일기 등) 기사 목록 + 상세.
- SQLite import 없이 JSON 직접 읽기. 파일시스템에서 바로 읽어서 동기화 문제를 없앨 것.
이렇게 구현됐다
메인 화면 — CORPUS + DB 카드 브라우저
앱을 열면 내가 가진 모든 코퍼스와 DB 번들이 카드로 나열된다. CORPUS 섹션에는 내가 직접 구축한 키워드 번들과 스레드 번들이, DB 섹션에는 크롤링 원자료가 소스별로 정리되어 있다. 카드를 클릭하면 해당 뷰어로 이동한다.
Keyword 뷰어 — 기사 목록 + 원문/번역 병렬
키워드 번들을 열면 기사 목록이 나오고, 기사를 선택하면 원문과 번역이 병렬로 표시된다. 메타데이터(저자, 날짜, 출처, 문체)는 접을 수 있는 패널로 처리해서, 텍스트에 집중할 때는 접어두고 필요할 때만 펼친다.

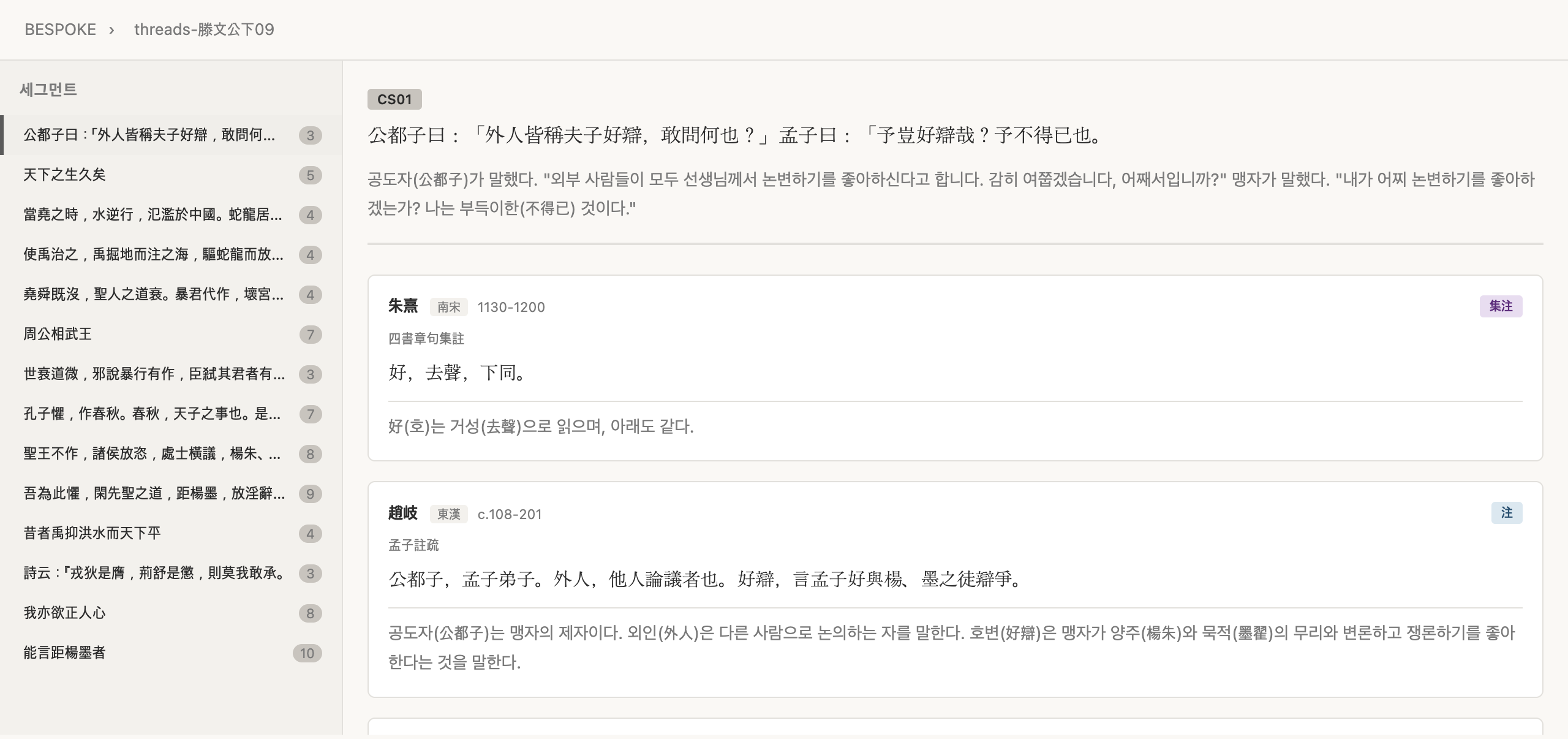
Threads 뷰어 — 경전 원문 + 주석가별 카드
내가 가장 공들인 뷰어다. 좌측 사이드바에 경전 세그먼트 목록이 나오고(주석 수가 배지로 표시된다), 세그먼트를 선택하면 우측에 경전 원문, 한국어 번역, 그리고 주석가별 카드가 펼쳐진다.
주석 카드 하나에는 주석가 이름, 시대, 생몰년, 주석 유형(배지), 주석 원문, 번역이 들어간다. 이런 식으로 같은 경전 구절에 대한 여러 주석가의 해석을 한눈에 비교할 수 있다. 논문에서 주석사(注釋史)를 다루는 내 연구 방식에 맞춰 설계한 레이아웃이다.
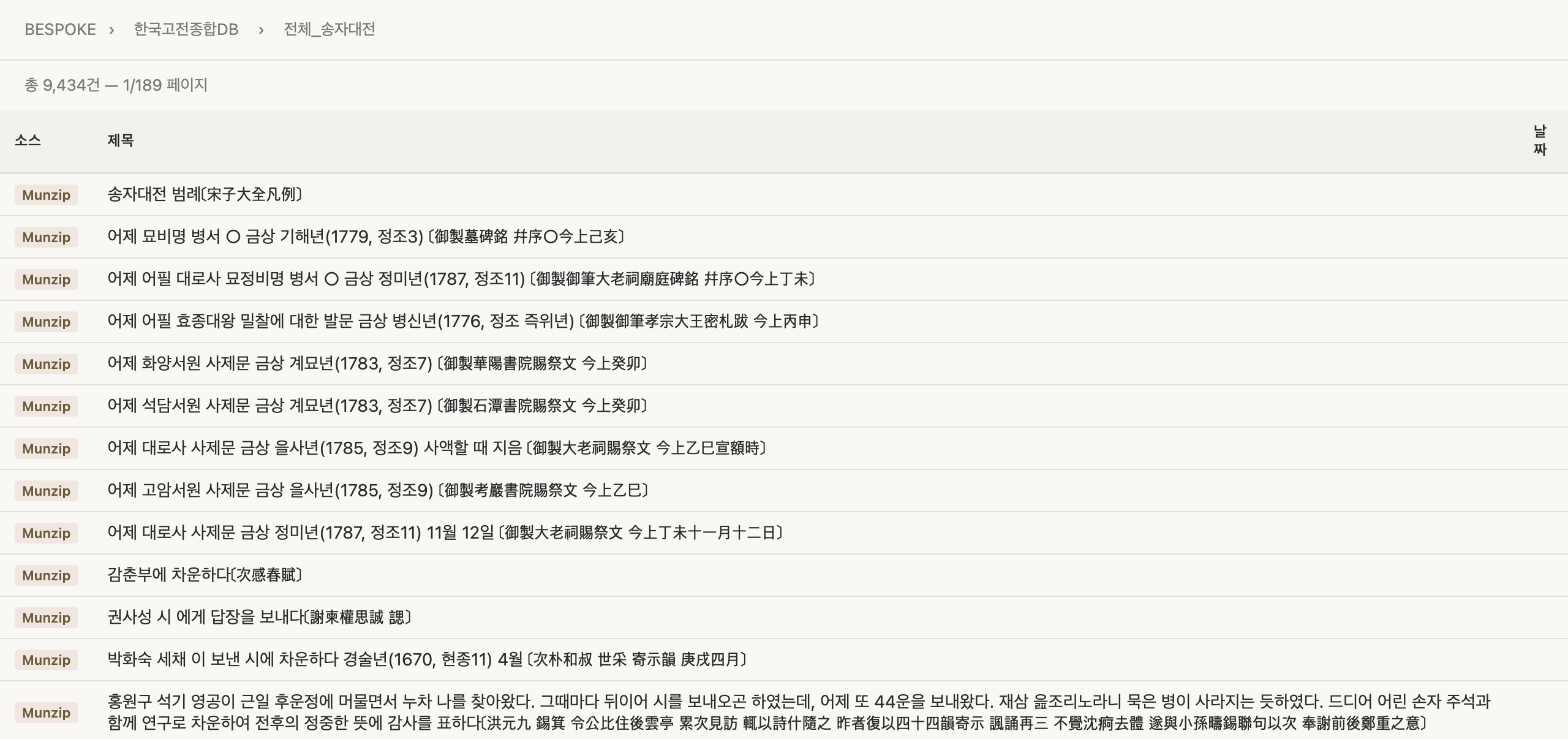
DB 뷰어 — 실록, 문집 등 원자료 열람
DB 뷰어는 keyword 뷰어의 구조를 재사용한다. 기사 목록 + 상세 화면. 다만 소스별로 메타데이터가 다르기 때문에(실록은 왕명/권차, 문집은 한자 제목/저자, 승정원일기는 날짜 등), 각 소스에 맞게 정규화해서 표시한다.
협업 관찰
이 앱은 Claude(Opus)와 만들었다. 전체 개발에 걸린 시간은 반나절 정도.
Claude가 한 것: Flask + Vanilla JS 기술 스택 결정, JSON 직접 읽기 방식의 캐싱 전략 설계(mtime 기반), 소스별 메타데이터 정규화 로직, FTS5 trigram 기반 CJK 전문 검색 구현, threads 뷰어의 세그먼트-주석 데이터 구조 파싱.
내가 한 것: 데이터 유형별(keyword/threads/DB) 열람 요구사항 정의, threads 뷰어에서 주석 카드 레이아웃과 표시 항목 결정, CORPUS와 DB를 통합 메인 화면으로 묶는 구조 결정, 각 뷰어 간 UX 차이 설계.
키를 잡은 건 내 쪽이었다. 이번에는 “어떤 기능이 필요한지”를 내가 명확하게 정의했다. JSON 직접 읽기나 FTS5 같은 기술적 결정은 Claude가 했지만, 무엇을 어떤 형태로 보여줄지 — 즉 뷰의 설계 — 는 내가 결정한 것이다. 연구자만이 자기 데이터를 어떤 형태로 봐야 유용한지 안다.
배움 포인트
사료 열람은 view이고, 내 해석을 붙이는 순간 materialize다. 크롤링한 사료 5만 건을 전부 .md 파일로 뽑을 필요가 없었다. JSON 원본이 있으면 언제든 원하는 형태로 꺼내 볼 수 있다. 실체화가 필요한 건 내 해석을 덧붙일 때뿐이다. 이 구분 하나로, 데이터 관리 부담이 크게 줄었다.
“나에게 맞는 방식으로 보고 싶다”가 앱 개발의 충분한 동기가 된다. 범용 뷰어는 범용적이라서 내 워크플로우에 안 맞는다. threads는 주석가별 카드로, keyword는 기사 목록 + 병렬 뷰로, DB는 소스별 정규화된 상세로 — 데이터 유형마다 최적화된 뷰를 만드는 건, AI 코딩 도구가 있으면 반나절이면 충분한 범위다. (개발 실력자라면 반나절도 안 걸릴 것이다.)